Devices still matter, Part 2: How attackers can use YOUR device
So based on our last post, we now know that MFA and Conditional Access can help prevent a lot of different scenarios involving “any old” devices. That leaves one other avenue for attackers then… Why bother trying to gain new access through any device when there are perfectly good devices out there that already have access? How about… your device?

I’m not just talking about physically lost or stolen devices, although that is also a concern and you need to have coverage for it (proper device management should allow you to remotely kill access and wipe corporate data from devices). I’m talking about getting virtually hijacked and not even knowing it.
This is not theoretical–some of the attacks I have discussed on this site before, like the Evilginix thing we talked about yesterday, or the OAuth app consent–those are all possible and have been demonstrated by security research to be effective at walking right past many of our favorite security controls, but in reality we don’t see those out in the wild much (yet). It’s the basics that get people compromised–e.g. patching, passwords, phishing.
Users get phished every day. And a decent percentage of successful phishing attacks will get workstations infected every day–very often by malware that does not have a signature. Some malware doesn’t even rely on files or changes to files, and that presents a special problem to many conventional security tools.
This is how it normally goes down:
9 times out of 10 (literally), it’s a successful phish that leads to a breached workstation–probably an exploit or installation of a bad software package. Don’t think that this can’t happen to you. It can. It certainly can. It could even happen to me, and I consider myself to be a pretty smart dude when it comes to this stuff. But I am also not naive enough to believe it could never happen to me. I could get tricked tomorrow. And so could you.
Now after you are breached, and for a long time, there will likely be screen captures and key logging that gets lots of valuable data out to attackers, especially from high-value targets. It is more valuable for them to stay hidden than to attempt doing anything destructive or noticeable right away.
They can see who you communicate with, and how often. They can see what you say and what you share. They can see account numbers, general ledgers, screens from your CRM, your ERP, your Accounting software, your password managers.
Mining this information helps them move into to even more targets inside or outside your organization (partners, customers, etc.). And it clues them in on how your business works and possible ways of monetizing their newly pwned assets.

Then the bad guys wait for the machine to go idle, and they can have more fun from there while you are sleeping. A trusted device often has loads of information and avenues into apps and data with very little barriers. Especially when people are saving passwords in the browser, leaving sessions open to apps or Remote Desktop environments, saving corporate data unencrypted to the local computer, or whatever. Attackers will probably also try to establish other footholds on that device and other nearby devices. Ultimately their goal is to gain domain admin or superuser status by moving into higher value targets. Again, this is not theoretical.
Story time
Real life example time:
- Retail operation across a tri-state region, probably ~1K seats
- Moved everything to Citrix-like environment, very few full workstations anymore, mostly dumb terminals
- Had no hardware or software inventory, limited central control (AV product only), no patch management, etc.–right down the list–none of the basic controls were met
- All retail sites connected via VPN and MPLS back to a central datacenter location
- Mainly this company just wanted an assessment of the server and network infrastructure (they didn’t care about endpoints)
Well, at the end of the assessment we told them that they didn’t need to start at their data center, which was already fairly well organized for everything else that was wrong. But rather, we suggested something totally unsexy, and I bet you guessed it: Go back to basics, start getting your inventory together, put in place a decent system to patch, monitor, protect and maintain your environment.
They didn’t like it, and guess what happened just a few short months later? Ransomware.
We still don’t know what kicked it off for sure, but most likely, someone was phished–clicked a link or downloaded something gnarly, and a workstation got infected. We do know they eventually got domain admin (thank you, Mimikatz), but the dates of those accounts were younger than the local accounts that we found established on several endpoints, prior to that.
From that first infected endpoint, the attackers were able to easily spread out across the network and infect other devices, including those dumb terminals.
The attackers had been in for months planning the ransomware execution. Backups were encrypted too but luckily this company had some offline copies we could go back to–and too few orgs take the offline backup thing seriously enough.
Now during the first restore effort they got reinfected. Why? Because the attackers were still in the network, even after we thought we had shut them out. It was like playing whack-a-mole because we didn’t yet have a complete inventory or picture of their network–so the attackers literally knew what was on the network better than we did, at first.
Eventually our team was able to deploy monitoring agents and an EDR out to every machine, round up all the affected endpoints and shut it down for good. Changed passwords across the board, disabled all other admin accounts and established a couple new ones of our own, etc. And luckily, restores were eventually completed also. But this process was several weeks long. I think I heard from the team that there was still a small, deprecated/legacy database of theirs that did not get restored, sadly. Again, simple inventory issue.
So guess who takes our recommendations now?
What would have prevented this from happening?
There are many places this could have been caught and stopped before it became a problem. The fact that they had no visibility to their own inventory was a huge part of the problem, not only for the restore process as I mentioned, but remember: without the inventory how do you know if you’ve got good patching, good secure configurations and so on? Like I said, the attackers established better visibility than their IT team.
Most of the endpoints were in fact missing antivirus and software updates here, especially the terminals. The devices did not have basic logging enabled on them either, so it was difficult to see much history or much detail to piece together “what happened.” I wish they had a couple of logging pieces in particular enabled, that they didn’t, which might have given us more detail, like all of these:
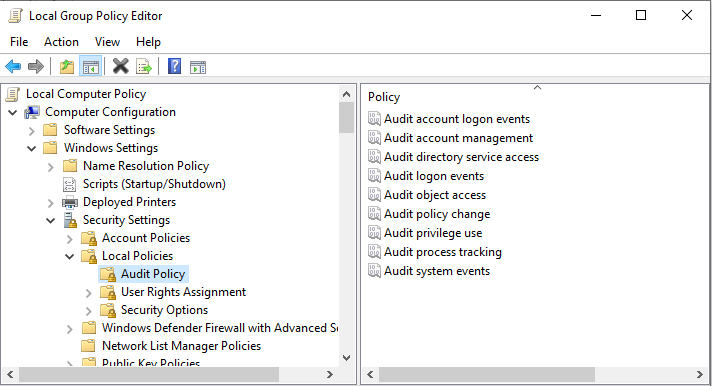
And especially all of these:
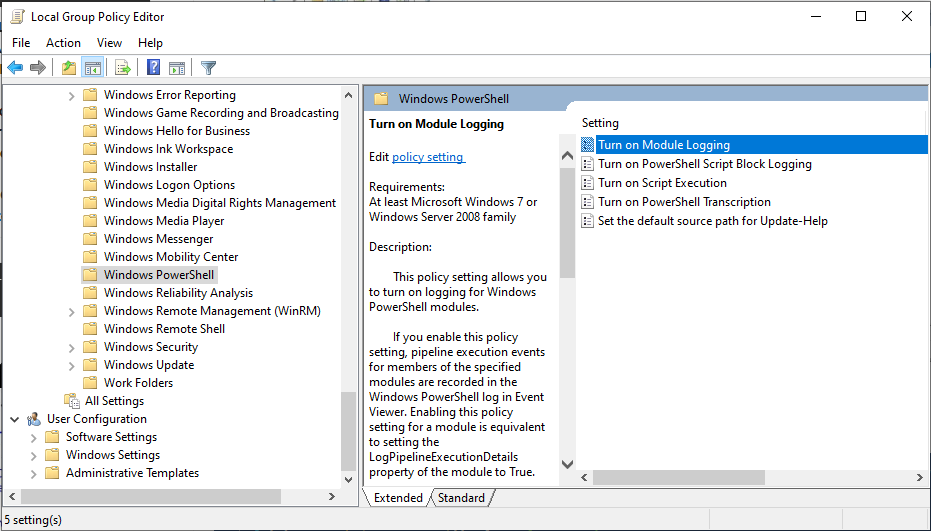
And that’s just for starters. Also, along with good logging, you should be able to surface interesting events and alert on them. This is probably going to mean adding a third party tool for most SMB’s. See CIS control #6: Maintenance, Monitoring and Analysis of Audit Logs. You should have some basic indicators of compromise bubbling up out of the “noise”–interesting items that you are watching for. You will want to know (and quickly) when stuff like this happens on a workstation:
- Activity or login at strange times of day
- Lateral movement, new user profiles
- New local accounts (footholds)
- Strange apps or tools show up that shouldn’t be there
- New or replaced system files like DLL’s, etc.
- Wiping the local event logs
- And more
Now remember this shop wasn’t even doing the basics, right? So more advanced security configurations like implementing Credential Guard, Exploit Guard, etc. was just not going to happen. Egress filtering? Application white-listing? Again, not realistic for folks who have NO INVENTORY, but those measures also would have prevented a lot of the shenanigans that the attackers were up to once inside the network.
As I mentioned, we ultimately deployed an EDR here, and undoubtedly had it been in place already, we would have seen suspicious activity coming from that, and endpoints that were infected or phoning home could have been identified and shut down.
Microsoft’s EDR product is called Microsoft Defender ATP (MDATP), and as of today it isn’t available with the Business SKU, only Enterprise. But it will also produce valuable insights into activity that should be shut down or at least investigated.
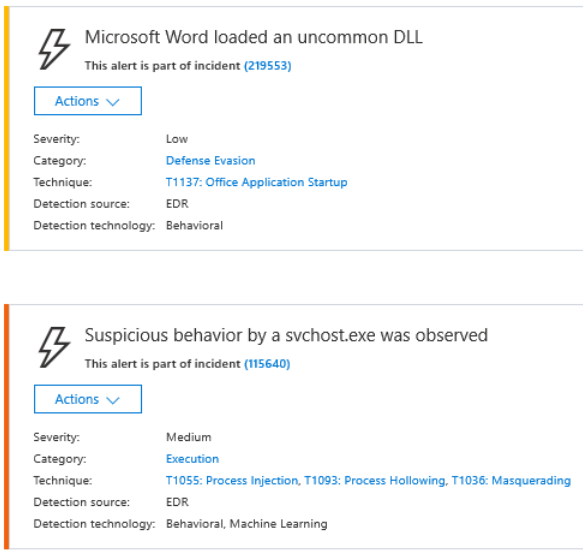
I personally hope they bring this, or at least a basic version of it, down to the SMB soon. Until then, it’s still third party tools for us SMB folk: Cylance, Carbon Black, Sophos, CrowdStrike, Panda, Palo Alto and many others out there–all of them have advanced EDR products with AI capabilities, that will help alert and stop threats as they unfold on the endpoint, much like MDATP.
But again, these types of protections belong in organizations who are further down the security maturity path. You can’t just slap this stuff in place and ignore the basics like inventory and control of devices–because you have no assurances all of your endpoints are even covered without that inventory. So it would have been nice to have these items in place, but honestly they would have needed to do some other things here, first.
Driving the point home
It maddens me to no end when I do a security assessment with a customer and I tell them: “You don’t have any kind of visibility or control over your endpoints. That is the first and most important thing you need to be working on, per the control frameworks CIS and NIST.” And they nonchalantly respond as though that can be tackled later–maybe next year or the year after.
Me: Um… What? Did you hear anything I just said to you?! It’s the most IMPORTANT thing–not that other stuff, THIS!!!
People think about the cloud like this customer thought about their fancy Citrix environment. Everything of importance is out there in the big shiny datacenter; the endpoints are nothing. They tend to want to focus only on the server-side and the cloud apps, and/or they want to chase some new thing they read about or heard about on their favorite security podcast (without wondering where that fits into the larger framework), and they imagine all this activity puts them in a better security posture.
But I got news for you: So long as you continue to ignore the basics, IT DOESN’T HELP! And on top of it, you’re still being an idiot. A complete dumb-dumb. A sucka that the bad guys are going to target, pillage, and then laugh at, as they walk away with your data and formerly good reputation. I’m not saying this to be mean, it’s just true.
The bottom line is: stuff happens on your endpoints. Stuff you want to know about. And, you may or may not get an indication based purely on the audit logs in your cloud apps that anything is the matter, until it is too late, and there has already been a lot of exfiltration and/or damage done simply through the compromised workstation.
The end user, and the endpoints themselves–that’s the new edge of your network. So you cannot afford to ignore your devices, or put that project off another year. Even if it seems trivial because devices are “replaceable” or because they are so few in number (that doesn’t make them less valuable targets, folks).
And to be clear, I don’t mean to suggest that BYOD is out and it’s just fully managed and secured devices across the board–you can still offer BYOD where it makes sense. In some extra sensitive environments I probably wouldn’t, honestly. But for typical information workers this can be done, but to do it well takes a more nuanced approach, and a willingness or ability to live with a little more risk, too. I’ll have some more thoughts on that thread to share later.
Small business customers SOL?
Security is not outside the reach of small business customers. And it’s actually a lot simpler than most people make it out to be in their mind. Your job is to start with those first few basic security controls, and then work your way up the chain from there. Eventually, you are ready for fancier footwork. But walk before you run. Here they are again for reference:
- Inventory and Control of Hardware Assets
- Inventory and Control of Software Assets
- Continuous Vulnerability Management
- Controlled Use of Administrative Privileges
- Secure Configuration for Hardware and Software on Mobile Devices, Laptops, Workstations and Servers
- Maintenance, Monitoring and Analysis of Audit Logs
When you get down to the last one on this list, at a minimum, you can (and should) enable some extra logging on your workstations too (not just cloud services or whatever). If you have a nice SIEM or other tool that can collect and parse all the data, great! But if not, it’s still good to have a record to refer back to, so you can piece together how things went down in the event of a breach or other security event, like we talked about.
When you reach this stage you will want to look into some better tools that will help you aggregate and make sense of all the data. In the Microsoft world, there are various “advanced” protections and tools that can help you gain a leg up. We have stuff like Advanced Threat Analytics, Azure ATP, and the mighty Microsoft Defender ATP. Not all of those are available to Business customers, as I mentioned (your plan needs to have an “E5” in it as of today to get into a lot of that stuff).
Last of all, just remember: when you aren’t managing those endpoints or paying attention to the audit logs, then the attackers get to have lots of fun. And usually for a very long time before they are actually discovered. So don’t be a sucka. Stop taking those stupid pills. Tackle the controls with your customers, starting with #1. You are informed now, so you have no excuse if you continue in your old sucka ways, and end up compromised as a result.
Leave a Reply