It’s all about your downtime tolerance
Before you go picking the cheapest possible IT solution that meets your business requirements, or on the other side of the equation, adding unnecessary complexity to your network, you first need to consider: What is your downtime tolerance? If you don’t answer this critical question, you might end up with a solution that cannot live up to expectations, or again on the other side of the spectrum, you might end up paying interest on a debt that is not actually owed. “Right-sizing” is key to successful implementations that meet budget, business objectives and expectation.
So how do we define downtime tolerance? Here’s how:
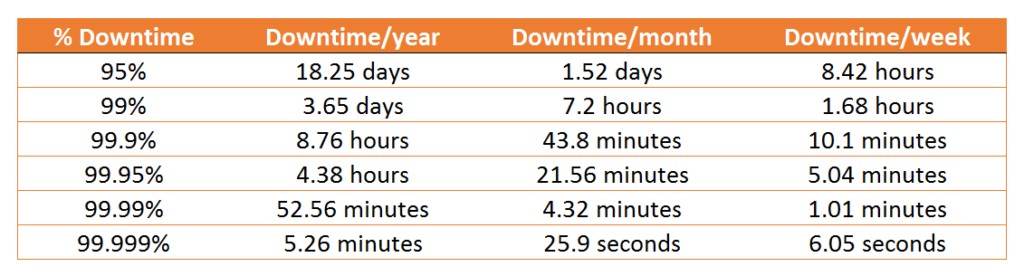
Let us take the above and break it down into three simpler categories, assuming one major failure or “Murphy” incident occurs per year (and that may be stretching the definitions a bit here since you can never assume anything about Murphy, but bear with me).
SMB On-Premises, and On a Budget
The first category is where a lot of small businesses live–between 95-99% up-time. Granted, 95% probably provides less coverage than most small businesses could tolerate these days, and ever since virtualization came to our market, even 99% is much easier to achieve, even when you’re on a budget. Here is how I would build an ~99% up-time solution:
- Single, warrantied host server running production virtual machines
- Separate backup repository such as a NAS, and software e.g. DPM, Veeam, Altaro or similar
- I would also insist on a secondary / replica repository of the same backups be stored offsite
- Even better if you have quicker access to secondary host server hardware
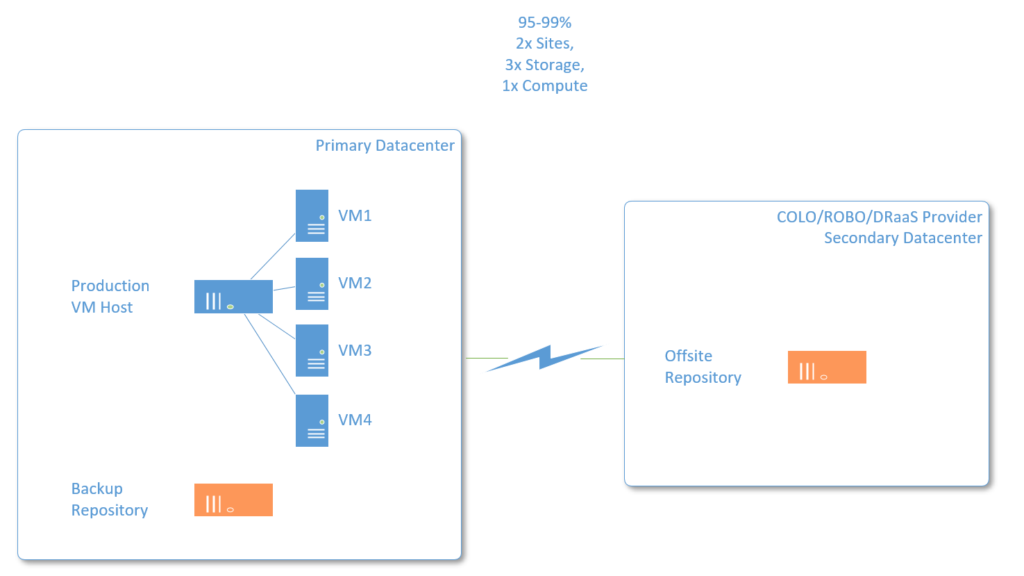
With this solution, even if there were an unexpected hardware failure, you should be able to troubleshoot and get parts replaced under warranty within an appropriate time frame, then restore the virtual machines, to return to full production.
Depending on the warranty, and other circumstances around the disaster event, you may fall a bit shy of full 99% coverage here, but certainly you could expect better than 95%, assuming only a single outage or failure/year. With multiple Murphy incidents such as these in a year, or loss of your entire production site (e.g. tornado, fire, etc.) you might miss your 99% SLA, but still.
Assuming you spent just a little more money to improve these numbers and move solidly into the realm of two-nines or better, you could simply add a full secondary host server, or trade out your NAS repositories for host servers capable of running your production workloads, at least temporarily, until hardware can be fully repaired. You’re basically just adding two additional compute nodes to the solution (rather than “dumb” storage devices like NAS for backups).
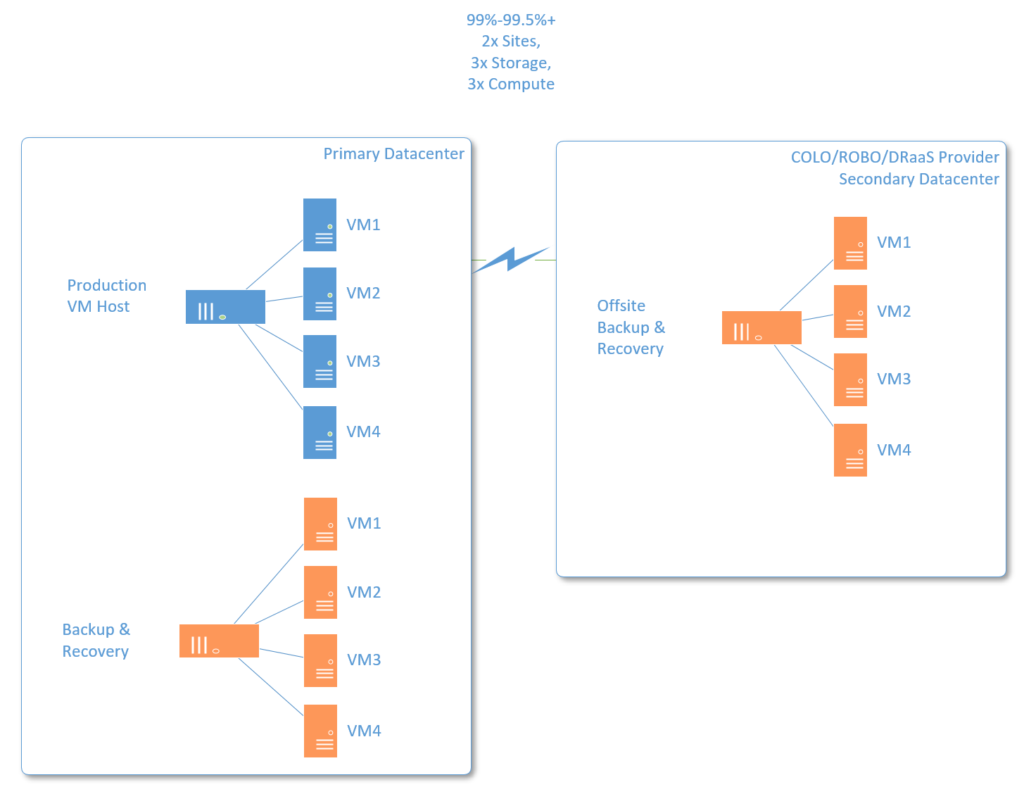
If troubleshooting a failure doesn’t yield promising results in an hour or so, you can just choose to virtualize from your backup images to this alternative hardware, for a certain period of time. At this point, you might even be approaching “three nines”–especially if you have virtualization capabilities built-in to your offsite backup repository/server.
Highly Available Workloads for the SMB
Now let’s talk about a solid three nines or better (given our assumptions). One of my all-time favorite solutions is one that I’ve been selling for many years to small and mid-sized businesses. These are organizations that typically have less than a couple of dozen virtual machines, and downtime is less palatable. Instead of buying a single host server capable of running virtual machines, I recommend two host servers, usually attached to a fully redundant shared storage solution. Now your virtual machines can automatically reboot on the opposite host in case one fails–further limiting your reasons to enter DR procedures from backup.
- Two warrantied host servers + shared storage, clustered together for virtualization
- We still require separate backup repository as described above
- We still require separate offsite backup, with the capability to virtualize there as well
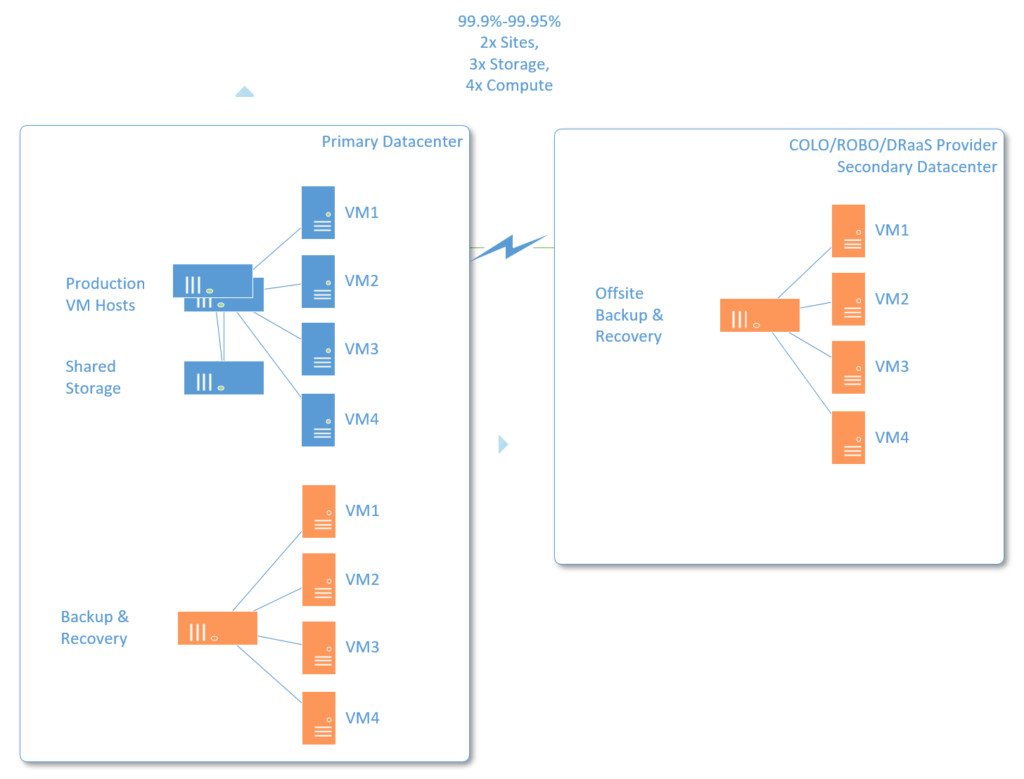
Remember: High Availability (HA) is not the same as having a backup–you still need a backup. Another important thing to note here is that we’re only sitting somewhere between 3 and 3.5 nines for up-time. Some people assume that we should be hitting four nines or better at this point, but that’s simply not true. The reason it isn’t true is because you are not protected against every type of Murphy.
Even if you say, “Well I run that solution in my data-center, and I was down for less than an hour last year…“–yes, because you were lucky. For example, your fault domains in this solution do not include application-level protection, only hardware and/or site level fault-tolerance. Your ability to recover within your main location is probably better than your ability to recover offsite, etc. So when people make these estimations based on their own feelings, they aren’t usually thinking about the whole picture. If you’re lucky, then having this solution can often feel like three nines or better (but realistically that isn’t accurate).
This is why Azure requires you to deploy two of every virtual machine into an “Availability Group”–which is just an object in Azure that tells the automated deployment engine to place each of the two VM’s into separate racks/fault domains. And that gives Microsoft the ability to boast a 99.95% up-time SLA (they offer a 10% credit if they fail to meet this SLA). With two of each virtual machine performing the same job, you have both hardware and application level availability (sometimes referred to as Continuous Availability).
Continuous Availability and why most SMB’s are choosing SaaS
You might assume that you could simply build your own version of this 99.95% up-time service model on-premises, perhaps by having two host servers with virtual machines that are basically mirror roles of one another, but you’d still be wrong. Why? Because the average SMB is most likely designing this infrastructure with fewer fault domains than Azure or AWS, e.g. they probably own a single rack/closet in a single site, with only one source of power coming into the building, etc.
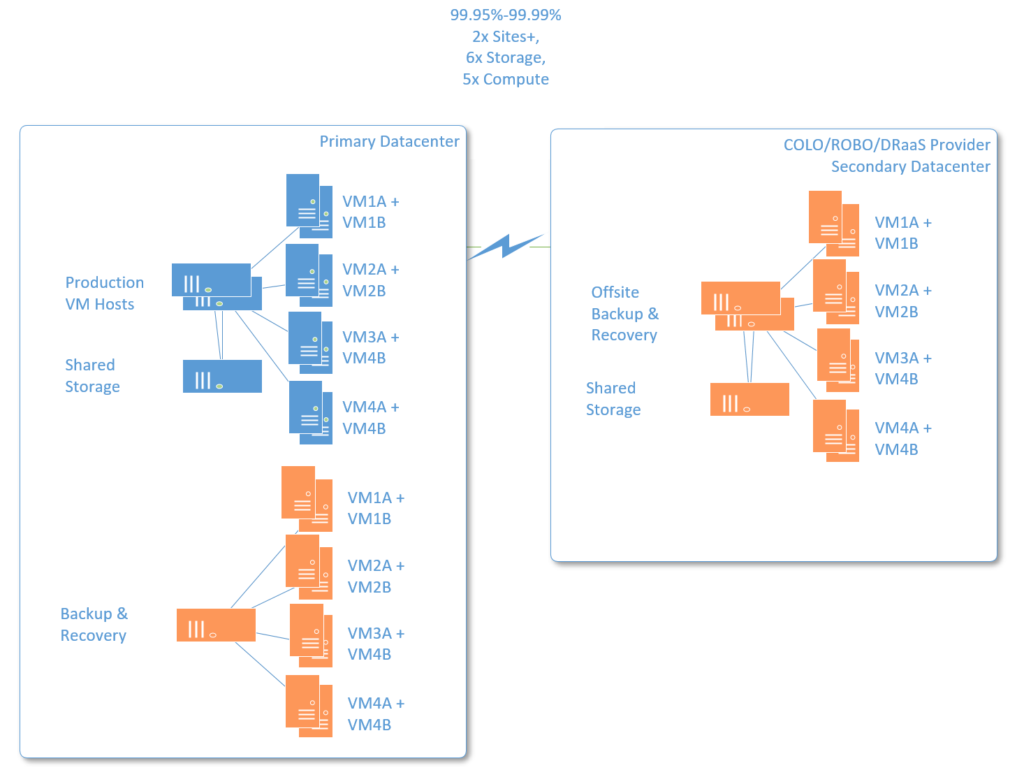
Notice how quickly storage needs multiply here, since we are doubling the number of virtual machines (and you may even consider a third DR site). So while it is possible to approximate toward the 99.95% or better up-time SLA with the right fault domains, sites and planning, most SMB organizations have not moved beyond three nines, at least when dealing with their own infrastructure. We typically part ways as we get into this arena–four nines and beyond–these service levels are usually only achievable in the large Enterprise, or in the public cloud. And that is one of the primary reasons we are seeing such large adoption rates for services like Office 365. Just check the record–you would not be able to replicate these numbers in your rinky-dink SMB network–you just won’t.
The jump from category #1 (backup & warranty only) to category #2 (High Availability) usually about doubles the cost of the infrastructure or better, in terms of hardware alone. You may have to spend double or more yet again to move into the Continuous Availability category, depending on the workloads (and remember: it’s not just about hardware in this case, but the expertise to set it up right and maintain it moving forward also). But to achieve this result in the cloud? Just few mouse clicks and one credit card later, and you’re paying a monthly fee to consume that Continuously Available service.*
For this reason, when a mid-sized IT shop comes to me and says, “Can you build us an Exchange DAG?” or, “We want two of every virtual machine…” I usually just smile and reply, “Why don’t we talk about your downtime tolerances first? If you still want to move in that direction, let’s at least compare your infrastructure requirements to the options in the cloud.” The right solution is usually self-evident after that.
————————————————————————————————-
*Interestingly, the effect of this cost doubling is still affecting you in the cloud, if you’re building IaaS (Amazon or Azure for example). Plus, you still need to enable a backup in these platforms, and that is additional to the service of Virtual Machines that you are already purchasing in duplicates. So when I walk through the costs of adding another “9” in the cloud, most of my clients recoil and fall back to three nines with on-premise infrastructure, where they can also take depreciation, etc. But, when we look at services like Office 365 (and other SaaS products) the value proposition is usually just too good and the price too attractive to ignore. The reality is, we can’t do this in your data-center as well as Microsoft or other providers can in theirs.

Comment (1)
Best article content for this topic on the internet! way to go! amazing.