A framework for implementing Device configuration profiles with Microsoft Intune
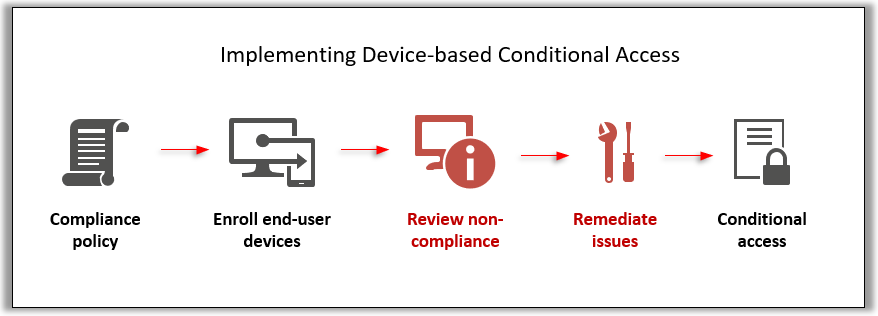
Last time we looked at the proper methodology for rolling out Device-based Conditional access in conjunction with Compliance policies. In that article, we observed that the workflow is very linear and logical, flowing from one step to the next, and ending in Conditional access, like so:
Device configuration profiles, on the other hand, require a circular methodology, using deployment rings. You normally start with a pilot group, and move out to larger waves thereafter.
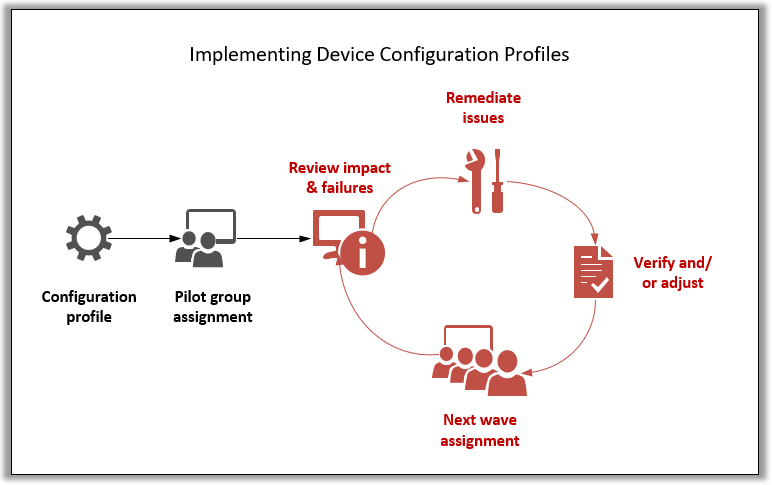
Again the steps highlighted in red are the ones I always see skipped, which usually means inconsistent configurations at the very least, and sometimes associated end-user-impacting issues. The most common mistake is just creating a configuration profile and pushing it to all users, then never circling back to review profile failures and to clean up the outstanding errors.
Side-note: Device configuration profiles will not have any bearing on Conditional access (they are not evaluated as part of compliance). So they will not affect a user’s ability to gain access to resources, one way or another.
Reviewing and resolving issues
Just like with compliance, we can also monitor Device configuration. Do you see yet why Intune is so much better than what we had with Group Policy? Could you have this type of feedback before?

Granted, if some setting fails to apply, the error messages they give you in the Intune portal today are completely unhelpful, but it’s still nice that we can know in advance exactly which devices and which settings we need to look at, without going up to every device individually to run rsop.msc or gpresult. Still gets us further than GPO ever did.
Why this circular approach matters
But there are other reasons you need to use deployment rings–it’s not just about remediation of errors in applying the profiles themselves. Some of the settings have a potential to negatively impact user experience (e.g. Exploit Guard), and therefore it is always a good idea to assign these incrementally starting with a pilot group, so that you can observe any impacts and learn how to eliminate them, or barring that possibility, at least to mitigate or communicate the impacts in advance of the full roll-out.
It could be something minor, like a reboot–Credential Guard for instance will most likely trigger a reboot to enable virtualization-related services. But you still want to flesh out the full scope of changes in your plan and communications before you hit the rest of the user base at large.
Also, if you can make any adjustments to the policy so that the next round of users is less impacted (adding excluded folders or apps to your Defender antivirus policy for example), then that is also to your benefit. Eventually as you loop through this process a couple more times, you will not need to proceed to a next wave (because your final wave is “All users”).
That about covers it–be sure to use deployment rings, and practice looping through testing and verification with your pilot groups until you are comfortable with the results. Then move those assignments into production as the last step.
Leave a Reply